Grammatically
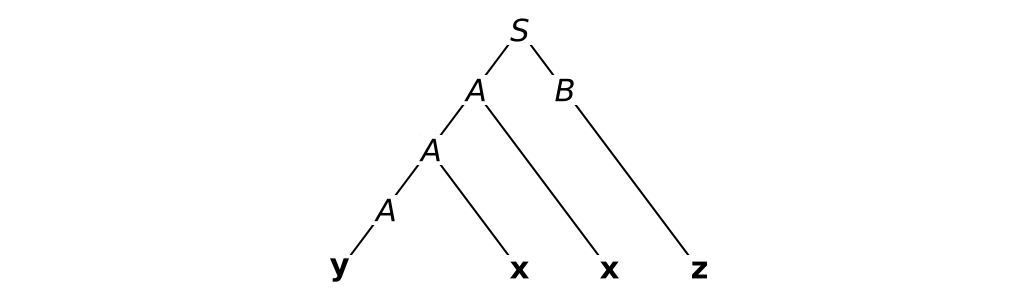
- Parse tree for yxxz:
Parsing Sentences
Apply successive productions.
Consider parsing the sentence yz using this grammar:
S AB A A x|y B z
We use three productions:
S AB (giving sentential form AB) A y (giving sentential form yB) B z (giving the sentence yz)
This is a leftmost derivation.
We could instead have used:
S AB (giving the sentential form AB) B z (giving the sentential form Az) A y (giving the sentential form yz)
This is a rightmost derivation.
Whilst the resulting parse tree is the same, the order of the the derivation governs the order in which the language structures appear in the parse tree as it is built.
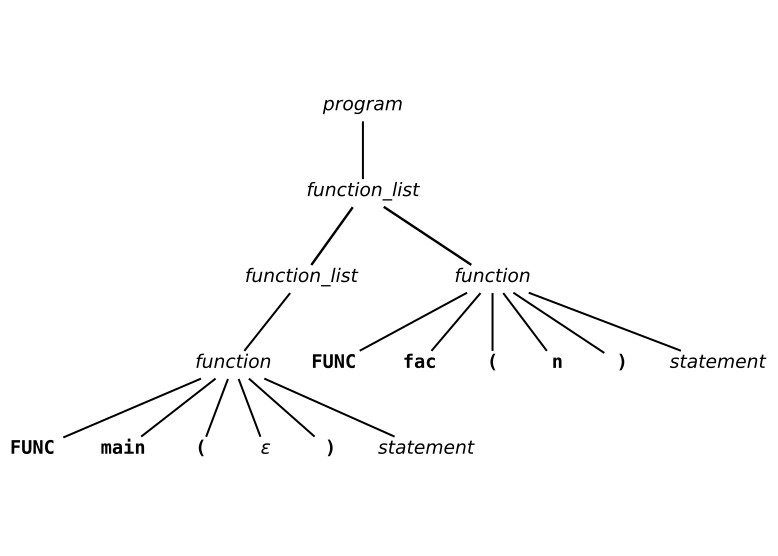
C Representation
struct node {
int nodetype;
struct node *field1;
struct node *field2;
struct node *field3;
struct node *field4;
struct node *field5;
}nodetypecan be defined as small constants:
#define NT_PROGRAM 1
#define NT_FUNCTION_LIST 2
#define NT_FUNCTION 3
...Simplification
No need for a program node, use function_list.
Avoid lexical detail, for example:
integer digit | integer digit digit 0 | 1 | … | 8 | 9
Just add a appropriate fields to struct node:
struct nnode {
int nodetype;
struct node *field1;
...
struct node *field5;
char *name; // variables and text
int value; // integer constants
}DAGs for Parse Trees
A DAG (Directed Acyclic Graph) can allow us to share common parse tree structures. It saves space and identifies possible common sub-expressions for optimisation.
However, they are hard to construct and syntactic identify does not mean semantic identity.