Learning Outcomes
- Make one definition of a network computing application.
- Present an example of a network computing application.
- Discuss the importance of resource sharing.
- Define seven major issues in distributed systems and network computing against your example.
Definition
A network computing application is one in which hardware and software components located at networked computers communicate and coordinate their actions only by passing messages.
The main reason for network computing is resource sharing.
Consequences
- Concurrency.
- No global clock (no global anything).
- Control is distributed - how do you coordinate actions and applications?
- Independent failures.
Examples
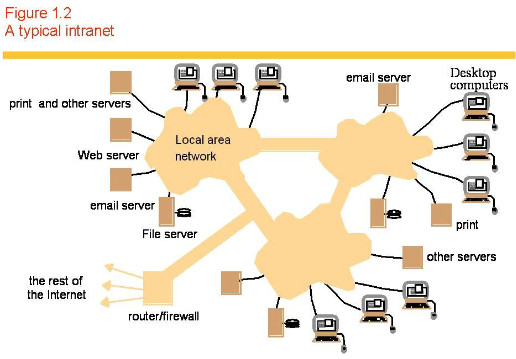
- Internet and Intranets (supporting role).
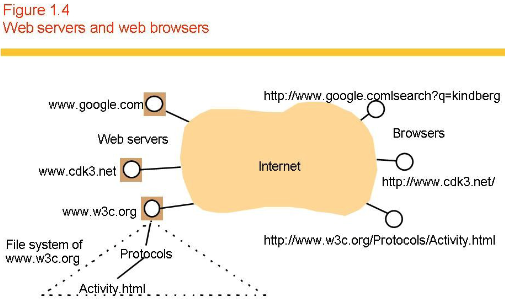
- The World Wide Web (supporting role?).
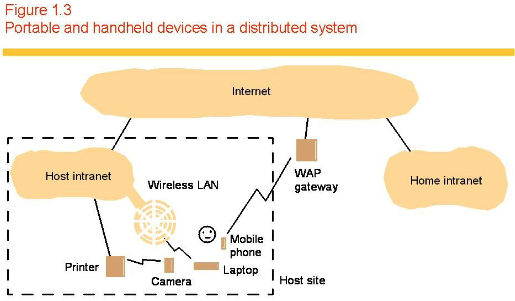
- Mobile applications.
- Games.
- Grid computing and Cloud computing.
- Virtual Working Environments.
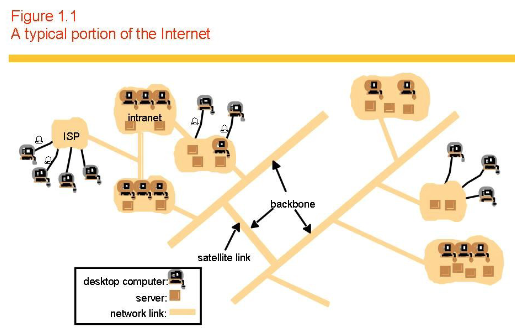
The Internet
- A collection of physical networks connected together via routers in a wide area network.
- Unique addressing (IP).
- Common protocol (TCP/IP).
- Name resolution service (DNS).
- Common service provision (socket-based services) to support email, the web and all sorts of services required for interoperation.
Virtual Working Environments
They used to be called Groupware. It is a client tool that allows you to connect to a central server:
- Schedule meetings.
- Conference calls.
- Application sharing.
It is everywhere: Zoom, Teams, gaming environments etc.
Games
There are plenty of multi-player games out there, just about every new game has “Internet” facilities.
- Real time vs “Turn”-based.
- Not usually cross-platform (interoperability).
- Digital objects for sale!
Grid Computing
A client sits on your computer and periodically takes work from a server.
It is simple, scalable computing.
1 million computers engaged in tasks such as:
-
SETI.
-
Molecular modelling.
-
Fight against malaria.
-
Process farming.
-
Grid.
-
Volunteer computing.
-
Cloud computing.
SAKERGRID Architecture
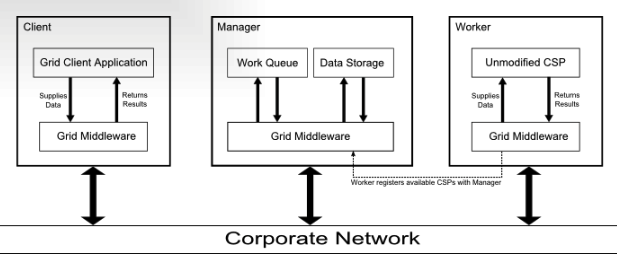
E-Infrastructure Architecture
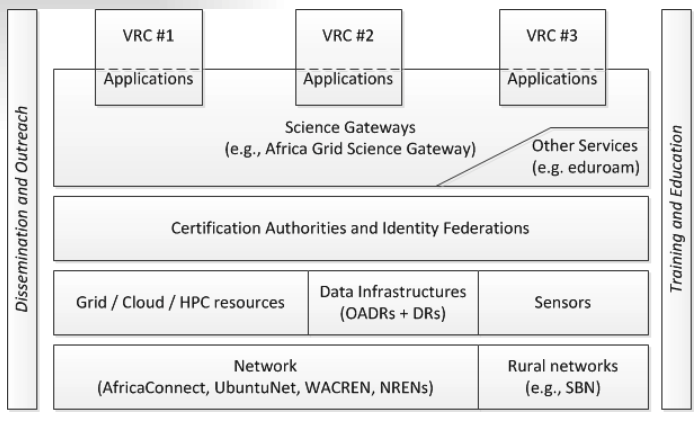
Service Oriented Architecture
The roots of SOA compare:
- Single-tier client-server architecture.
- Two-tier client-server architecture.
- Multi-tier client-server architecture.
- Distributed Internet architecture.
- RPC architecture.
To:
- Wrapper services.
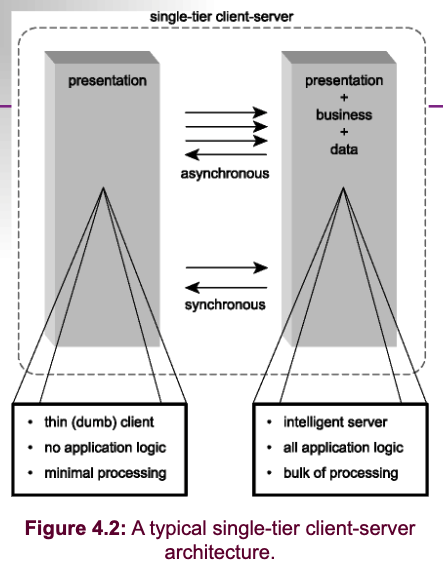
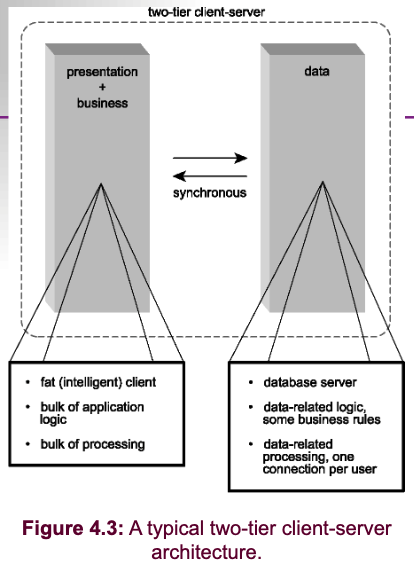
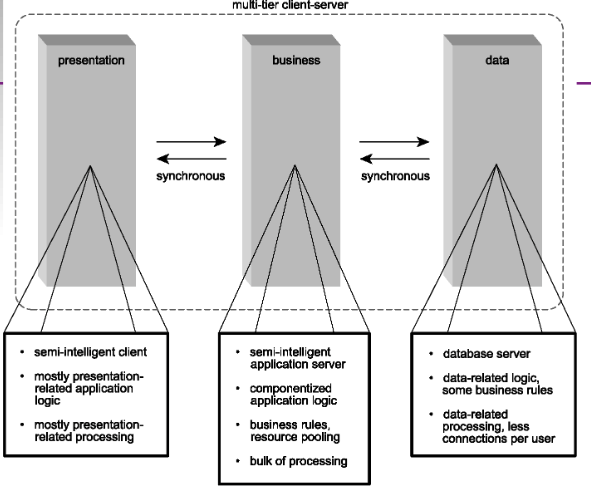
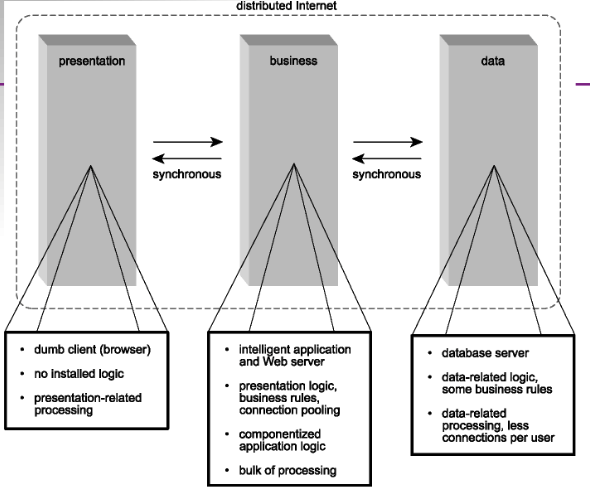
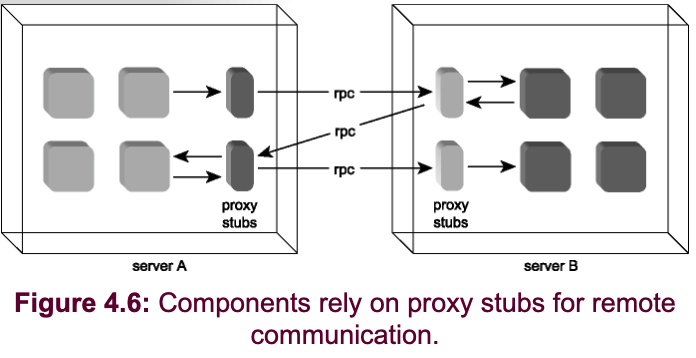
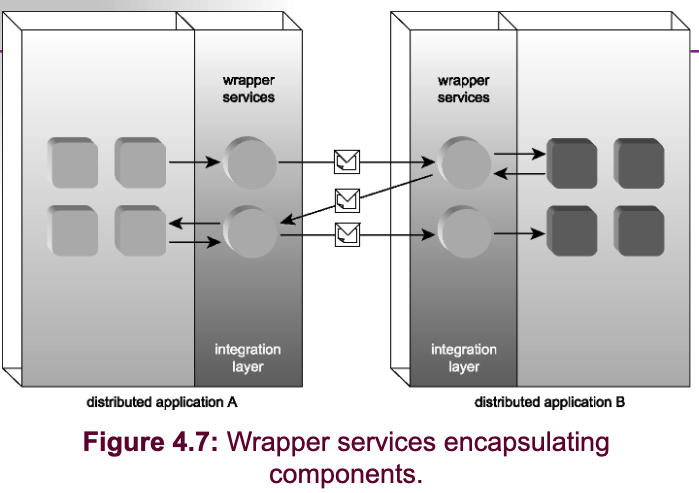
Seven Major Issues of Network Computing/Distributed Systems
Heterogeneity
Distributed systems often involve different types of devices, operating systems, programming languages, and communication protocols. These differences can make it challenging to ensure seamless communication and cooperation among various components within the distributed system.
Openness
Openness is the degree to which a distributed system is open to integration and interaction with other systems. It involves adhering to standards and protocols, enabling interoperability, and promoting flexibility in system design.
An open system might have:
- published interfaces.
- uniform communications mechanism and provision for access to shared resources.
- heterogeneous hardware and software (experimentation, testing, verification, accreditation).
Security
Security concerns focus on protecting data, resources, and communication within a distributed system. Ensuring confidentiality, integrity, and availability while defending against threats and vulnerabilities is a critical aspect of network computing.
Issues:
- Confidentiality (disclosure).
- Integrity (alteration or corruption).
- Availability (authorisation).
Major problems:
- Distributed Denial of service attacks.
- Security of mobile code:
- Policy!!!
- MSBLASTER.
- Phones.
- Cars?.
Scalability
Scalability involves the ability of a distributed system to handle increased load or growing user demands. Designing for scalability ensures that the system can efficiently expand by adding resources or nodes as needed.
- Add more physical resources!
- Control the cost
- Maintain the performance!
- Control performance loss
- Add more software resources!
- Stop them from running out
- Avoid bottlenecks!
- Really share the resources
Failure Handling
Failure handling deals with addressing faults and errors within the distributed system. It includes strategies for detecting, isolating, and recovering from failures to maintain system reliability and availability.
- Detect them!
- how can you detect something that is no longer there?
- Hide (mask) them!
- Retransmit messages.
- Redundancy/Replication.
- Tolerate them!
- Tell the user or make them wait?
- Find something else?
- Recovery from them!
- How?
- Redundancy.
- Replication vs consistency.
- Availability and Service Provision.
- The 99% con (95 = 18.25, 99 = 3.65).
Concurrency
Concurrency relates to managing multiple tasks or processes concurrently within a distributed system. It’s essential to ensure efficient resource utilisation and responsiveness while dealing with potential synchronisation challenges.
- The fine art of doing two or more things at the same time.
- Or do you?
- Synchronisation techniques and critical regions.
- Serialisability.
- Decent programming models!!!!
- Threads vs Message passing.
- Shared memory vs distributed memory.
- Parallel computing vs distributed computing.
Transparency
Transparency aims to hide the complexities of a distributed system from users and applications. Achieving transparency means providing a consistent and uniform interface and behaviour regardless of the system’s underlying complexity and distribution.
- Hiding complexity from the user.
- ANSA and ISO (RM-ODP) recognise eight types.
- Access: enables local and remote resources to be accessed using identical operations.
- Location: enables resources to be accessed without knowledge of their physical network location (for example: which building or IP address).
- Concurrency: enables several processes to operate concurrently using shared resources without interference between them.
- Replication: enable multiple instances of resources to be used to increase reliability and performance without knowledge of the replicas by users or application programmers.
- Failure: enables the concealment of faults, allowing users and application programs to complete their tasks despite the failure of hardware or software components.
- Mobility/migration: allows the movement of resources and clients within a system without affecting the operation of users or programs.
- Performance: allows the system to be reconfigured to improve performance as loads vary.
- Scaling: allows the system and applications to expand in scale without change to the system structure or the application algorithms.
- Access and Location = Network Transparency
Reading
- Coulouris: chapter 1.